
Data preparation is the process of gathering, combining, structuring and organizing data so it can be analyzed as part of data visualization, analytics and machine learning applications.

The components of data preparation include pre-processing, profiling, cleansing, validation and transformation; it often also involves pulling together data from different internal systems and external sources.
Data preparation work is done by information technology (IT) and business intelligence (BI) teams as they integrate data sets to load into a data warehouse, NoSQL database or Hadoop data lake repository. In addition, data analysts can use self-service data preparation tools to collect and prepare data for analysis when using data visualization tools such as Tableau.
Purposes of data preparation
One of the primary purposes of data preparation is to ensure that information being readied for analysis is accurate and consistent, so the results of BI and analytics applications will be valid. Data is often created with missing values, inaccuracies or other errors. Additionally, data sets stored in separate files or databases often have different formats that need to be reconciled. The process of correcting inaccuracies, performing verification and joining data sets constitutes a big part of the data preparation process.
In big data applications, data preparation is largely an automated task, since it could take years of work by IT staffers or data analysts to manually correct every field in every file that's due to be used in an analysis. Machine learning algorithms can speed things up by examining data fields and automatically filling in blank values or renaming certain fields to ensure consistency when data files are being joined.
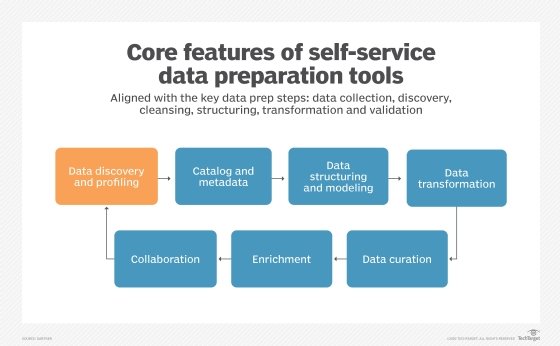
Data preparation process
After data has been validated and reconciled, data preparation software runs files through a workflow, during which specific operations are applied to files. For example, this step may involve creating a new field in the data file that aggregates counts from preexisting fields, or applying a statistical formula -- such as a linear or logistic regression model -- to the data. After going through the workflow, data is output into a finalized file that can be loaded into a database or other data store, where it is available to be analyzed.
Even though data preparation methods have become highly automated, it can still take up significant amounts of time -- especially as the volume of data used in analyses continues to grow. Data scientists often complain that they spend a majority of their time locating and cleansing data rather than actually analyzing it.
Partly for that reason, there has been an increase in the number of software vendors attempting to tackle the data preparation problem, and many organizations are putting more resources toward automating data preparation. In 2017, data visualization vendor Tableau added self-service data preparation as part of its software, using machine learning methods to simplify the data preparation process.
Benefits of data preparation
One of the biggest benefits of instituting a formal data preparation process is that users can spend less time finding and structuring their data.
Many enterprises have implemented data lakes, often built around Hadoop data stores, where they store large amounts of semistructured and unstructured data. When a data scientist needs a data set for an analysis, they have to hunt down the data first. With a formal data preparation process in place, repetitive analyses can be fed data automatically, rather than requiring users to locate and cleanse their data each time.